LEVIR-CD is a new large-scale remote sensing building Change Detection dataset. The following NLST datasets are available for delivery on CDAS.

Drive Dataset Papers With Code
The EUVP Enhancing Underwater Visual Perception dataset contains separate sets of paired and unpaired image samples of poor and good perceptual quality to facilitate supervised training of underwater image enhancement models.

. When you select Refresh here the data in the files model is refreshed with updated data from the original data source. Additionally the dataset consists of rich annotations at both image-level and head-level. The script also serves as a reference implementation of the automated scheme that we used to align and crop the images.
We contribute DeepFashion database a large-scale clothes database which has several appealing properties. When you set up a refresh schedule Power BI connects directly to the data sources. Alternatively you can download the Train-Val-set videos and annotations from our Google-Drive folder.
Download and Visualize using FiftyOne. Google Drive Download link for. See our Google Drive folder containing all Twitch files.
The total number of points in this dataset is about 15 million and the total distance of the trajectories reaches 9 million kilometers. We maintain the data using Google Drive and Baidu Yunpan. We have collaborated with the team at Voxel51 to make loading visualizing and evaluating ActivityNet a breeze using their open-source tool FiftyOne.
These datasets can assist in a variety of tasks including tool testing developing familiarity with tool behavior for given tasks general practitioner training and other unforeseen uses that the user of the datasets can. First DeepFashion contains over 800000 diverse fashion images ranging from well-posed shop images to unconstrained consumer photos. This is a sample of T-Drive trajectory dataset that contains a one-week trajectories of 10357 taxis.
Download link for Wukong100m. Data Dictionary PDF - 989. You should submit a zip file which contains one jsonl file in the top-level directory.
L7iv Google Drive Overview of LEVIR-CD. Statistics of different types of objects. GoogleNews-vectors-negative300bingz - Google Drive.
The zip file contains a separate csvgz file for each user in the dataset. As with any other dataset in the FiftyOne Dataset Zoo loading ActivityNet is as easy as calling. We are hosting multi-object tracking MOT and segmentation MOTS challenges based on BDD100K the largest open driving video dataset as part of the ECCV 2022 Self-supervised Learning for Next-Generation.
This chart also shows the diverse set of objects that appear in our dataset and the scale of our dataset more than 1 million cars. This kind of refresh entirely from within the Power BI Desktop application itself is different from manual or scheduled refresh in. Once you have downloaded the in-the-wild images with python download_ffhqpy --wilds you can run python download_ffhqpy --align to reproduce exact replicas of the aligned 10241024 images using the facial landmark locations included in the metadata.
The whole dataset is split into 256 files each contains around 80000 pairs. العربية Deutsch English Español España Español Latinoamérica Français Italiano 日本語 한국어 Nederlands Polski Português Русский ไทย Türkçe 简体中文 中文香港 繁體中文. Geospatial Distribution of LEVIR-CD.
It then updates any report visualizations and dashboards based on that dataset in the Power BI service. Retinal vessel segmentation and delineation of morphological attributes of retinal blood vessels such as length width tortuosity branching patterns and angles. After unzip the file files under the data root directory is.
CelebA has large diversities large quantities and rich annotations including 10177 number of identities 202599 number of face images and 5. The baseline code for 3D-RetinaNet used in the dataset release paper uses sequences of frames as input. ECCV 2022 BDD100K Challenges.
Whether you want to increase customer loyalty or boost brand perception were here for your success with everything from program design to implementation and fully managed services. The reader should be reminded here that those are distinct objects with distinct appearances and contexts. Each image in this dataset is labeled with.
World-class advisory implementation and support services from industry experts and the XM Institute. Then Power BI loads the updated data into the dataset. The introduced dataset would be a new benchmark for evaluating change detection CD algorithms especially those based on deep learning.
Power BI uses connection information and credentials in the dataset to query for updated data. Once you have downloaded the videos from Google-Drive. Primary data - features and labels.
1 Jing Yuan Yu Zheng Xing Xie. CelebFaces Attributes Dataset CelebA is a large-scale face attributes dataset with more than 200K celebrity images each with 40 attribute annotations. Recommendation on Live-Streaming Platforms.
The videos of Test-set is released you can download it from our Google-Drive folder. The file full_acsvgz contains the full dataset while 100kcsv is a subset of 100k users for benchmark purposes. The DRIVE database has been established to enable comparative studies on segmentation of blood vessels in retinal images.
Odgt is a file format that each line of it is a JSON this JSON contains the whole annotations for the relative imageWe prefer using this format since it is reader-friendly. The evaluation server is available on CodaLab. We support annotation_trainodgt and annotation_valodgt which contains the annotations of our dataset.
If you use the dataset for your published work you are required to cite the ExtraSensory original publication mentioned here as Vaizman2017a. 4372 images Contains 4372 images with an avg resolution of 1430x910 collected under a diverse set of conditions and various geographical locations. Dataset fiftyonezooload_zoo_datasetactivitynet-200 splitvalidation.
Submission formats and evaluation metrics for classification task and detection task are described in tutorial part-2 and part-3 respectively. The extraction code for Baidu Yunpan is noah. You can perform a one-time manual refresh in Power BI Desktop by selecting Refresh on the Home ribbon.
It has substantial pose variations and background clutter. Learn more about Dataset Search. Dynamic Availability and Repeat Consumption.
The code is available in our Github repository. Also provides a means to link SCT image files to participants and where those images are batched in either a hard drive delivery or Lung Cancer Selection download. Second DeepFashion is annotated with rich information of clothing items.
Welcome to the new and improved Computer Forensic Reference DataSet Portal. Our dataset is also suitable for studying some particular. For each dataset a Data Dictionary that describes the data is publicly available.
Please cite the following papers when using the dataset. This portal is your gateway to documented digital forensic image datasets. Digital Retinal Images for Vessel Extraction.
Please cite the following if you use the data. Please go to our discussion board with any questions on the BDD100K dataset usage and contact Fisher Yu for other inquiries.

Nighttime Driving Dataset Papers With Code
Stare Dataset Papers With Code

Ddd17 Dataset Papers With Code

Discovering Millions Of Datasets On The Web Google Today Data Science Data Scientist

Discovering Millions Of Datasets On The Web Google Today Data Science Data Scientist
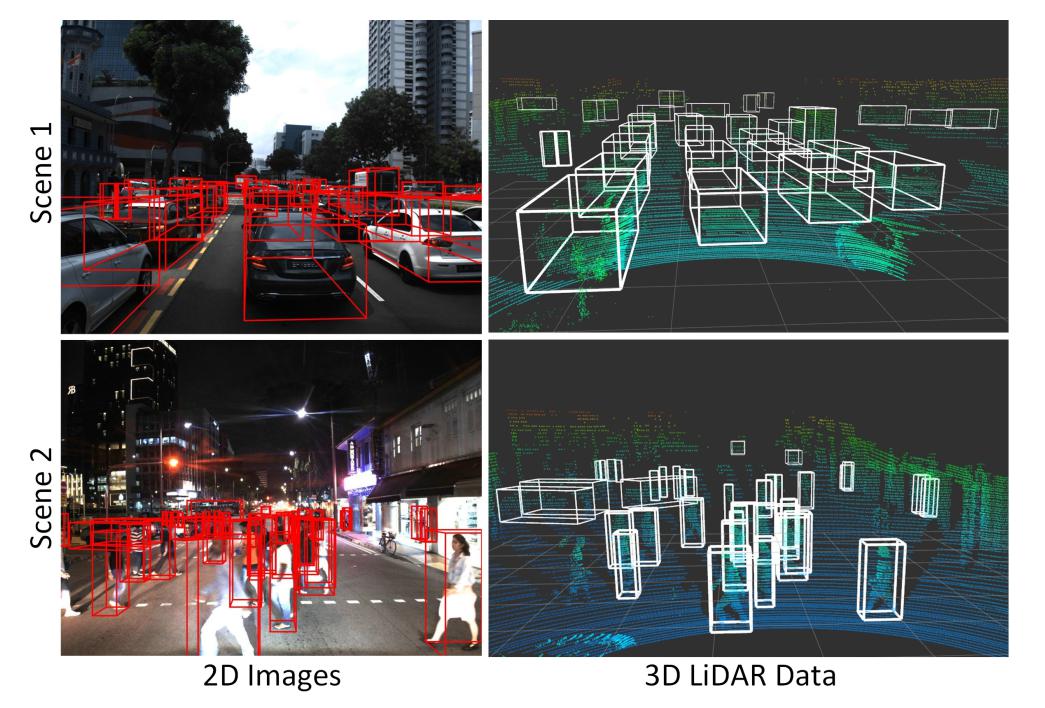
A 3d Dataset Papers With Code

Uc Berkeley Has Open Sourced The Largest And Most Diverse Dataset On Self Driving Cars It Is Filled With Rich Annotat Self Driving Open Source Computer Vision

Cae Email List Chief Audit Executive Mail Address Cae Mailing List Execution Email List
0 comments
Post a Comment